








我们都知道,大模型肚子里只有训练时学到的那些知识,有一个“截止日期”。为了解决这个问题,RAG(检索增强生成,Retrieval-Augmented Generation)技术能让 LLM 遇到一个问题时,不再只靠自己的记忆,而是先去知识库里搜索相关的资料,然后再结合这些搜来的资料,生成一个有理有据的答案。
但RAG技术,也有短板,那就是它听不懂话里有话。评估一篇文章和用户的问题是否相关时,标准太粗糙、太单一了。它不能理解一个核心问题:人类语言的“词汇多样性”。
这导致了RAG辛辛苦苦搜来一堆看似相关,实则没什么用的资料,把真正有价值的信息给漏掉了。拿着一堆垃圾信息,再厉害的 LLM 也做不出好文章。
词汇多样性感知的检索增强生成(Lexical Diversity-aware RAG,DRAG)方法应运而生。

AI 的“阅读理解”难题
词汇多样性到底是怎么把 RAG 搞糊涂的呢?主要体现在两个阶段:检索阶段和生成阶段。
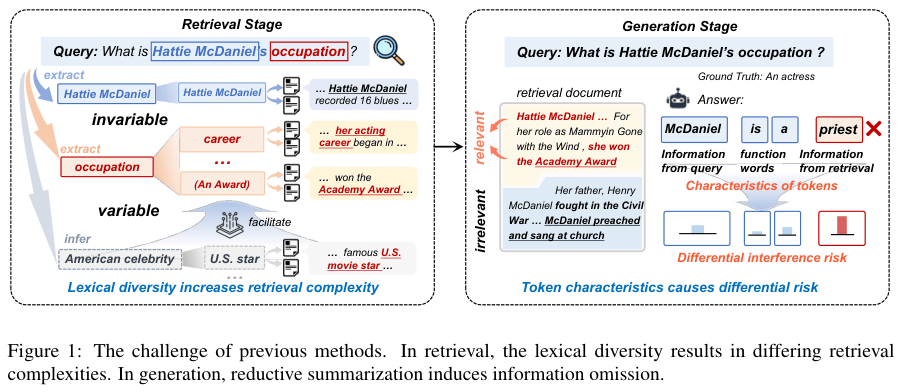
先说检索。
一个问题里的词,其实可以分成三类。拿一个具体的问题来举例:“海蒂·麦克丹尼尔的职业是什么?”
第一类,叫“不变组件”(Invariant)。比如问题里的“海蒂·麦克丹尼尔”,这是个专有名词,说一不二,形式是固定的。RAG 要做的就是去文档里找有没有这个名字,有就是相关,没有就是不相关,很简单。
第二类,叫“变体组件”(Variant)。比如问题里的“职业”。这个词的花样就多了。在别的文章里,它可能被描述成“专业”,或者是具体的工作,比如“演员”、“歌手”,甚至是她获得的成就,比如“奥斯卡金像奖得主”。这些不同的说法,本质上都指向“职业”这个概念。
第三类,叫“补充组件”(Supplementary)。这些词在问题里压根没出现,但是能帮助我们更好地理解问题。比如,和“海蒂·麦克丹尼尔的职业”相关的,可能还有“美国名人”、“非裔女演员”这些补充信息。这些信息也能帮我们判断文章的相关性。
你看,一个简单的问题,里面的词汇就这么复杂。
现有的 RAG 模型是怎么做的呢?它们一视同仁,用一个标准去衡量所有词。结果就是,一篇文档里虽然出现了“海蒂·麦克丹尼尔”,但通篇讲的是她的家庭生活,和“职业”八竿子打不着,可因为包含了那个不变的组件,RAG 还是会认为它很相关。而另一篇详细介绍了她演艺生涯和获奖经历的文章,仅仅因为没有出现“职业”这个原词,反而可能被 RAG 忽略掉。
这就是典型的“只见树木,不见森林”。
说完了检索,再说生成。
就算 RAG 运气好,搜到了一些有用的文档,但这些文档里也必然夹杂着大量的噪声和无关信息。模型在生成答案的每一个词时,都会受到这些噪声的干扰。
哪些词最容易被带偏呢?通常是那些构成答案核心事实的词,比如人名、地名、事件名。这些词往往是从检索来的文档里直接抽取的,如果文档本身就有问题,生成的答案自然就错了。而像“的”、“是”这种连词,或者“他”、“她”这种代词,受噪声的影响就小很多。
现有的 RAG 方法,要么就是对所有生成的词一视同仁,要么就是用一些复杂的算法去校准每一个词,这不仅计算量巨大,而且效果也不好。
庖丁解牛,让 RAG 开窍
DRAG 的核心思想,就是“具体问题具体分析”,它有两个法宝:一个是“多样性感知相关性分析器”(Diversity-sensitive Relevance Analyzer, DRA),另一个是“风险引导稀疏校准策略”(Risk-guided Sparse Calibration, RSC)。
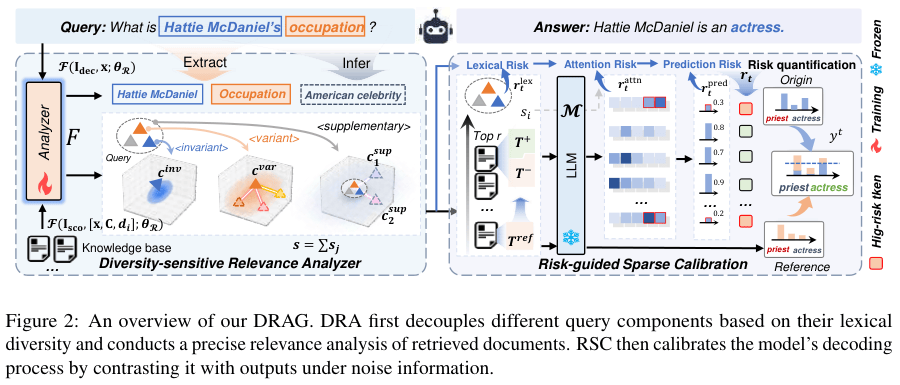
我们先看 DRA 是怎么工作的。它就像一个聪明的侦探。
拿到一个问题后,DRA 不会急着去搜索,而是先对问题本身进行“庖丁解牛”。它会把问题拆解成我们前面说的那三类组件:不变的、可变的和补充的。这个拆解过程,通过微调一个小模型来自动完成。比如,对于“波特兰是哪个州的首府?”这个问题,DRA 会把它拆解成:
- 不变组件:波特兰
- 变体组件:首府
- 补充组件:州或国家
拆解完之后,DRA 会为每一类组件设定不同的“相关性评估标准”。
对于“不变组件”,标准非常严格,就是“有”或“没有”。一篇文章里提到了“波特兰”,得分就是 1,没提到就是 0。
对于“变体组件”和“补充组件”,标准就灵活多了。DRA 会去评估文章内容是否在语义上和这些组件相关。比如,“首府”这个词,文章里就算没出现,但如果提到了“行政中心”或者描述了波特兰是某个州的政府所在地,那它也能得到一个比较高的连续分数(比如 0.8)。
最后,DRA 会给这三类组件的得分分配不同的权重(通常是“不变”的权重最高,“补充”的最低),然后加权求和,得出一个总分。这个总分,才是一篇文档和整个问题之间真正的、细粒度的相关性得分。
通过这种方式,DRA 就能精准地从一大堆文档里,把那些不仅包含了关键词,而且真正在讨论问题核心内容的文档给捞出来。
捞出了高质量的文档,接下来就轮到第二个法宝 RSC 出场了。它的角色,像一个“降噪耳机”。
RSC 的任务是在生成答案的阶段,把那些无关信息的干扰降到最低。但它不像其他方法那样对所有词都进行降噪,那样太浪费计算资源。RSC 采取的是“稀疏校准”,也就是只对那些“高风险”的词下手。
那怎么判断一个词的风险高低呢?RSC 会计算一个“无关风险”分数,这个分数由三部分组成:
- 词汇风险:如果原始问题的词汇多样性越高(也就是“变体”和“补充”组件越多),那么从文档里提取正确信息的难度就越大,风险自然就高。
- 注意力风险:模型在生成一个词的时候,如果它的注意力更多地放在了那些相关性得分较低的文档上,说明它可能被带偏了,风险也很高。
- 预测风险:如果模型在预测某个词的时候,本身就表现得非常不确定(比如,好几个候选词的概率都差不多),那说明它自己也没底,这个词受噪声影响的风险就很大。
把这三个风险乘起来,就得到了每个词的最终风险分。
接下来,RSC 会设定一个阈值。一旦某个词的风险分超过了这个阈值,RSC 就会启动校准程序。校准的方法也很有意思:RSC 会让模型假设只用最不相关的那篇“噪声文档”来生成这个词,看看会生成什么。然后,用模型在正常情况下的预测结果,减去这个“噪声结果”的影响。
这就好比,你在一个嘈杂的环境里听不清别人说话,RSC 帮你识别出噪音,然后从你听到的声音里把噪音给过滤掉,剩下的就是更清晰的人声了。
而且,这个过程只针对少数高风险的词,所以计算开销非常小。
DRA 负责“精挑细选”,RSC 负责“去粗取精”,两者配合,就让整个 RAG 流程的效率和准确性都上了一个大台阶。
DRAG的优越性能
把 DRAG 和当前最主流的一些 RAG 方法,比如 Self-RAG、FLARE 等,进行了一场全方位的对比。结果怎么样?
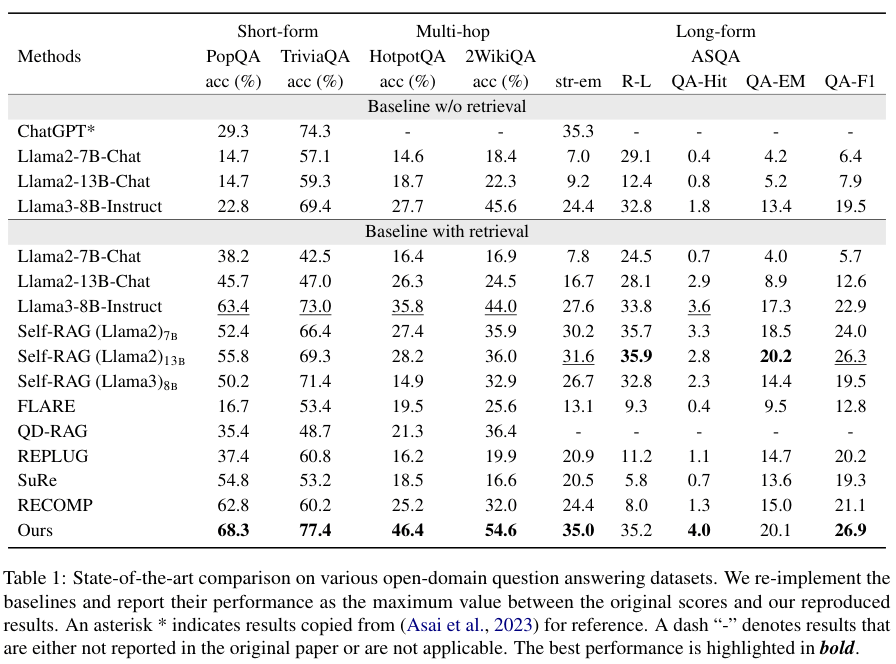
实验场景涵盖了短文本生成(比如 PopQA 和 TriviaQA)、长文本生成(ASQA)和需要多步推理的多跳问答(HotpotQA)。
可以说,DRAG 在几乎所有任务上都取得了领先。
在事实性要求极高的 PopQA 数据集上,基础的 LLM 自己回答的准确率惨不忍睹,而 DRAG 方法,准确率直接飙升了 45.5%。和目前最好的 RAG 方法相比,也高出了 4.9%。
在更复杂的多跳问答任务 HotpotQA 上,DRAG 的提升更夸张,准确率比次优方法高了整整 10.6%。这充分说明,问题越复杂,对词汇多样性的理解要求越高,DRAG 的优势就越明显。而且,训练数据里并没有多跳问答的数据,这还证明了 DRAG 的泛化能力非常强。
看一个具体的例子。

在 TriviaQA 的一个问题里,基线模型因为无法准确评估文档的相关性,被噪声信息干扰,给出了一个错误的答案。而 DRAG 通过它那套“庖丁解牛”加“降噪”的组合拳,精准地找到了正确信息,生成了正确答案。
为了搞清楚 DRAG 的成功到底归功于谁,把 DRA 和 RSC 这两个模块单独拿出来测试,做了“消融实验”。
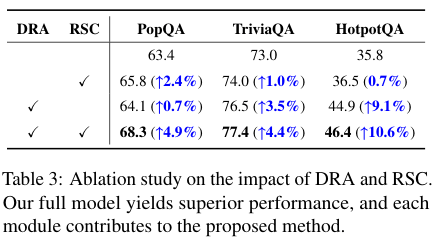
结果发现,只用 DRA,性能有提升;只用 RSC,性能也有提升。但只有当它俩合体时,才能发挥出最大的威力,达到 1+1>2 的效果。这说明,精准的检索和智能的生成校准,缺一不可。
DRAG 在不同大模型上,不管是 Llama2-7B 还是 Mistral-7B,都能给它们带来显著的性能提升,尤其是 Llama2-7B-Chat,准确率从 38.2% 一下子拉到了 67.0%,效果拔群。这证明 DRAG 是个通用插件,而不是某个专属模型的“外挂”。

计算成本如何?毕竟,效果再好,如果慢得像蜗牛,那也没法用。DRAG 和其他一些在生成阶段进行解码优化的方法对比。
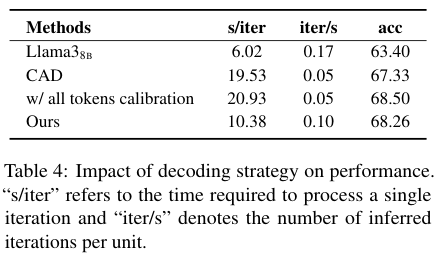
DRAG 因为只对少数“高风险”词进行校准,所以增加的计算开销非常小,几乎可以忽略不计。用最小的代价,换来了最大的性能提升。
看来,让 AI 真正理解人类语言的丰富性和复杂性,是提升其智能水平的关键一步。
参考资料:


